什么是HiveApache Hive是一款建立在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化数据文件映射为一张数据库表,基于表提供了一种类似SQL的查询模型,称为Hive查询语言(HQL),用于...
”hive spark 文档资料 hadoop 数据仓库“ 的搜索结果

Hadoop+Spark+Flink+Zookeeper+Kafka+Hbase+Hive完全分布式高可用集群搭建
CDH6针对hive on spark的调优文档,这个是生产的实战经验

众所周知,大数据开发和分析、机器学习、数据挖掘中,都离不开各种开源分布式系统。最常见的就是 Hadoop、Hive、Spark这三个框架了。最近不少朋友有问到关于这些的问题:大厂里还有在...
本文主要讲述的是Hadoop3.3.1-hive3.1.2-spark 3.3.1 以及其他组件的搭建与遇到的问题
Hive起源于Facebook,Facebook公司有着大量的日志数据,而Hadoop是实现了MapReduce模式开源的分布式并行计算的框架,可轻松处理大规模数据。然而MapReduce程序对熟悉Java语言的工程师来说容易开发,但对于其他语言...
Hive 是在 Hadoop 分布式文件系统 (HDFS) 之上开发的 ETL 和数据仓库工具 由 Facebook 实现并开源 Hive 提供写 SQL 的方式对存储在 Hadoop 集群里面的数据进行清洗、加工,生成新的数据并存储到 Hadoop 集群当中。 ...


前言: 前面的文章介绍了Hadoop的HDFS,YARN,SSH设置,本篇将承接上面的配置,继续介绍Hadoop相关的HIVE工具,本...hive是基于Hadoop构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop分...
Hive是基于Hadoop的数据仓库工具,可对存储在HDFS上的文件中的数据集进行数据整理、特殊查询和分析处理,提供了类似于SQL语言的查询语言–HiveQL,可通过HQL语句实现简单的MR统计,Hive将HQL语句转换成MR任务进行...
目录导读Hadoop、Hive 是什么运行环境hive-env.shhive-site.xmlcore-site.xmlhdfs-site.xmlmapred-site.xmlyarn-site.xmlhadoop-env.cmdJava 环境Mysql下载 Hadoop、Hive 和 驱动安装 Hadoop启动 Hadoop安装 Hive...
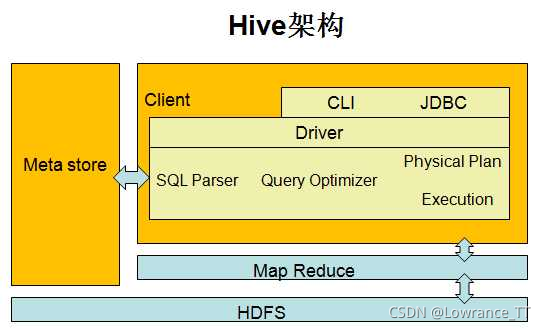
在远程模式下,所有的Hive客户端都将打开一个到元数据服务器的连接,该服务器依次查询元数据,元数据服务器和客户端之间使用Thrift协议通信。Hive支持三种不同的元存储服务器,分别为:内嵌式元存储服务器、本地元...
Hadoop的数据仓库Hive
标签: hive
Hadoop的数据仓库Hive Hive基本概念 由 Facebook 开源用于解决海量结构化日志的数据统计。Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类 SQL 查询功能。 本质是:将 ...
Hive 是 Facebook 开源的一款基于 Hadoop 的数据仓库工具,它能完美支持 SQL 查询功能,将 SQL 查询转变为 MapReduce 任务执行。这使得大数据统计得以实现。Hive 是最早的也是目前应用最广泛的大数据处理解决方案。 ...
Hadoop+Spark+Hive高可用分布式集群安装 集群规划 节点IP 节点别名 zookeeper节点 JournalNode节点 NodeManager节点 DataNode节点 zkfc节点 NameNode节点 ResourceManager节点 192.168.99.61 spark01 ...
spark 单机启动 spark-shell 集群启动 /usr/local/spark-2.4.5-bin-hadoop2.7/sbin/start-all.sh 提交任务 1.打包python环境: ...Hadoop是一个能够对大量数据进行分布式处理的软件框架。 特性: 高可

Spark 从Hive中读取数据2018-7-25作者: 张子阳分类: 大数据处理在默认情况下,Hive使用MapReduce来对数据进行操作和运算,即将HQL语句翻译成MapReduce作业执行。而MapReduce的执行速度是比较慢的,一种改进方案就是...

Hive是基于Hadoop的数据仓库工具,可对存储在HDFS上的文件中的数据集进行数据整理、特殊查询和分析处理,提供了类似于SQL语言的查询语言–HiveQL,可通过HQL语句实现简单的MR统计,Hive将HQL语句转换成MR任务进行...

数据仓库(英语:Data Warehouse,简称数仓、DW),是一个用于存储、分析、报告的数据系统。数据仓库的目的是构建面向分析的集成化数据环境,分析结果为企业提供决策支持思考:1、假如你现在手里有200w,当下的时间...
Hive是基于Hadoop HDFS之上的数据仓库。 我们可以把数据存储在这个基于数据的仓库之中,进行分析和处理,完成我们的业务逻辑。 本质上就是一个数据库 它可以来保存我们的数据,Hive的数据仓库与传统意义上的数据...


推荐文章
- YOLO V8车辆行人识别_yolov8 无法识别路边行人-程序员宅基地
- jpa mysql分页_Spring Boot之JPA分页-程序员宅基地
- win10打印图片中间空白以及选择打印机预览重启_win10更新后打印图片中间空白-程序员宅基地
- 【加密】SHA256加盐加密_sha256随机盐加密-程序员宅基地
- cordys 启动流程_cordys服务重启-程序员宅基地
- net中 DLL、GAC-程序员宅基地
- (一看就会)Visual Studio设置字体大小_visual studio怎么调整字体大小-程序员宅基地
- Linux中如何读写硬盘(或Virtual Disk)上指定物理扇区_dd写入确定扇区-程序员宅基地
- python【力扣LeetCode算法题库】面试题 17.16- 按摩师(DP)_一个有名的讲师,预约一小时为单位,每次预约服务之间要有休息时间,给定一个预约请-程序员宅基地
- 进制的转换技巧_10111100b转换为十进制-程序员宅基地